ObjectiveThe goal of this project is to create a smooth, reliable, and scalable way to bring all clinical and operational data into one unified platform. This will ensure that study data is consistently clean, organized, and ready for analysis without manual effort or delays. By modernizing how data is collected, prepared, and validated, we will make it easier for teams to access accurate information, reduce errors, and accelerate reporting. This solution will improve oversight, strengthen data quality, and enable faster, more confident decision-making across studies, sites, and stakeholders. Implement a workflow that sends the required study and billing updates back into Veeva after processing. 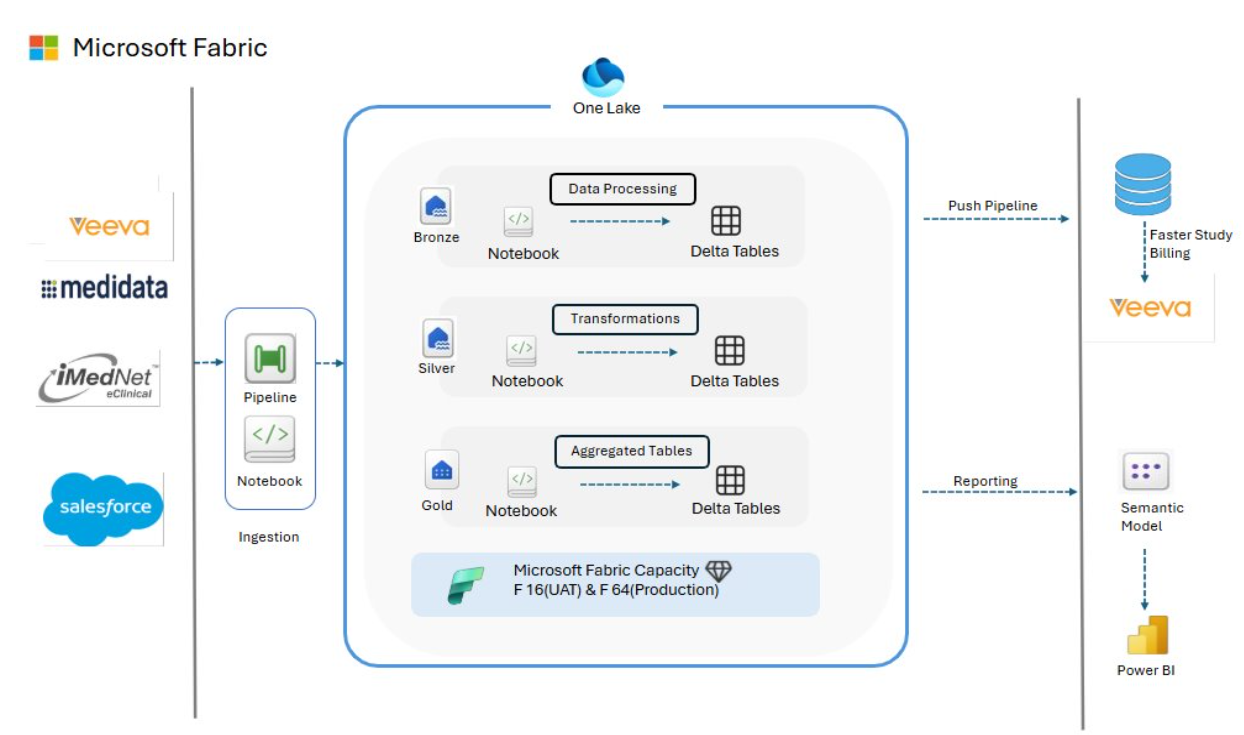
Technology1. Pipelines – Automated flows that bring data from different systems into one place. 2. Processing (Notebooks) – Tools that clean and prepare the data for use. 3. Lakehouse – A central storage layer for both raw and refined data. 4. Warehouse – A structured layer built for fast reporting and analysis. 5. Model – A simplified view of the data that makes reporting easier. 6. Dashboards – Visual reports that show insights and updates in real-time. Goals1. Centralize All Study Data – Bring data from diverse sources into one unified platform instead of multiple scattered systems. 2. Improve Data Quality – Clean, standardize, and validate all incoming data so it becomes accurate, consistent, and ready for reporting. 3. Enable Faster, Reliable Reporting – Make Power BI dashboards run faster by using Lakehouse storage, incremental loads, and optimized data models. 4. Reduce Manual Work – Automate data ingestion, transformation, and push-back processes to remove manual file handling and repeated work. 5. Support Study-Level Billing – Ensure correct and updated information is pushed back into Veeva to help the billing team generate accurate invoices. 6. Build a Scalable Architecture – Create a system that can easily handle more studies, more APIs, and new requirements in the future without major rework. Solution1. Connected All Sources – Integrated iMednet, Medidata, and Veeva into a single Lakehouse using secure API and SFTP connections. 2. Built Automated Pipelines – Set up Microsoft Fabric Pipelines to fetch, load, and refresh data automatically at scheduled intervals. 3. Structured the Data for Use – Organized the data into a clear, consistent format so teams can use it directly for reports and analysis. 4. Enabled Veeva Push-Back – Implemented a workflow that sends required study and billing updates back into Veeva after processing. 5. Used Fabric-Only Architecture – Designed using Microsoft Fabric tools, keeping the solution lightweight, simple, and cost-effective. Pre-Fabric Architecture Overview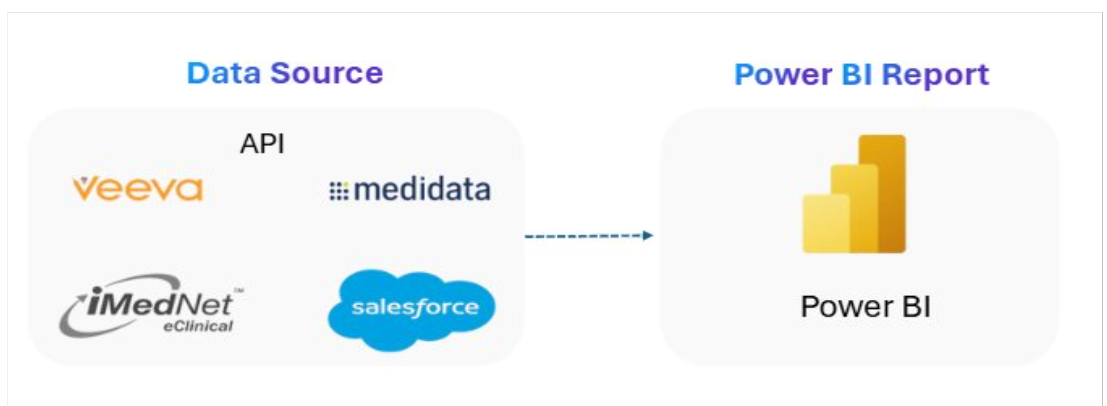
Before Fabric Implementation1. Power BI was directly taking data from APIs, making everything slow and dependent on API speed. 2. Reports took 5–6 hours to refresh because all data was pulled every time. 3. No centralized storage — no organized or reusable dataset. 4. No incremental load — the system downloaded all data instead of only new or updated records. Post-Fabric Architecture Overview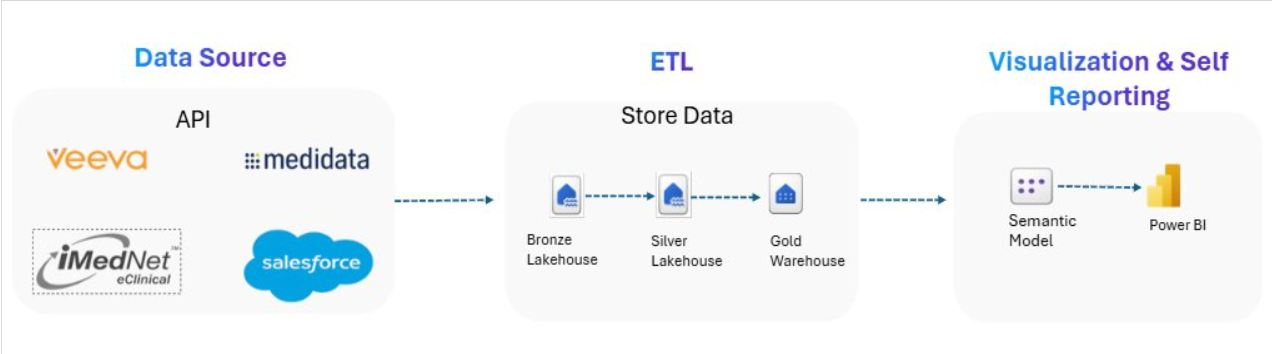
After Fabric Implementation1. All data now lands first in the Lakehouse through automated pipelines, giving one clean and organized place to store everything. 2. The data is processed through the Medallion Architecture (Bronze → Silver → Gold), making it structured, standardized, and ready for reliable reporting. 3. Power BI connects directly to the Lakehouse using Direct Lake, allowing dashboards to load instantly without depending on API calls. 4. Performance improved significantly because APIs are no longer repeatedly called; incremental loads reduced API traffic and improved stability. 5. Report refreshes are now stable and fast, completing in just 3–4 minutes instead of several hours. Previous Manual Process
1. Files were sent to Veeva through manual uploads such as Excel and CSV files. 2. High chances of human error. 3. No automated checks or validations. 4. No audit trail or version control. 5. Slow and inconsistent billing updates. 6. Processing large-scale data could take minutes, hours, or even days. Automated Push Pipeline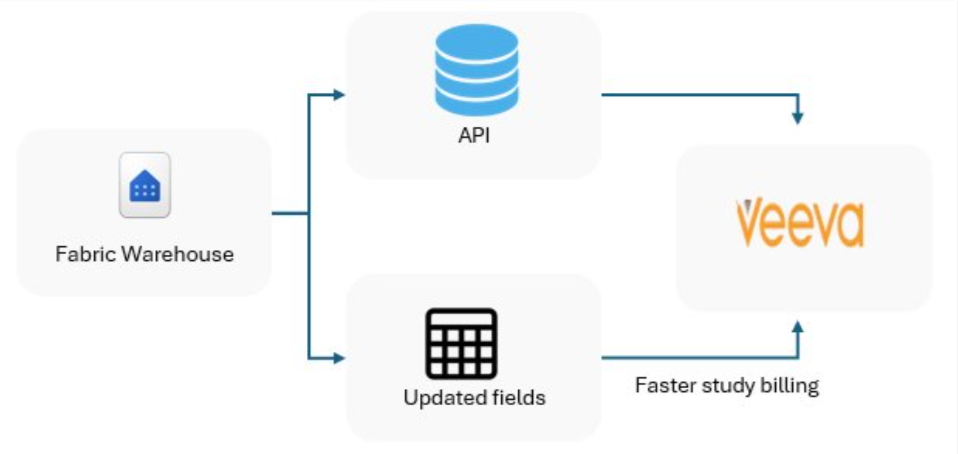
1. Fabric prepares and validates study data. 2. iMednet and Medidata data are pushed directly back into Veeva via pipeline. 3. Consistent, error-free updates. 4. Complete logging and audit trail. 5. Faster and accurate billing cycles. 6. Bulk processing enabled — approximately 30,000 records processed in under 2 minutes. 7. Maintain configuration. 8. A complete logging framework tracks every step of the push pipeline, including successes, validations, warnings, and errors, ensuring full transparency and traceability. |
HEALTHCARE & PHARMACEUTICALS
Clinical Research Organization : From Raw Data to Insights Through a Robust Data Pipeline
Share with your community!
SUCCESS STORIES